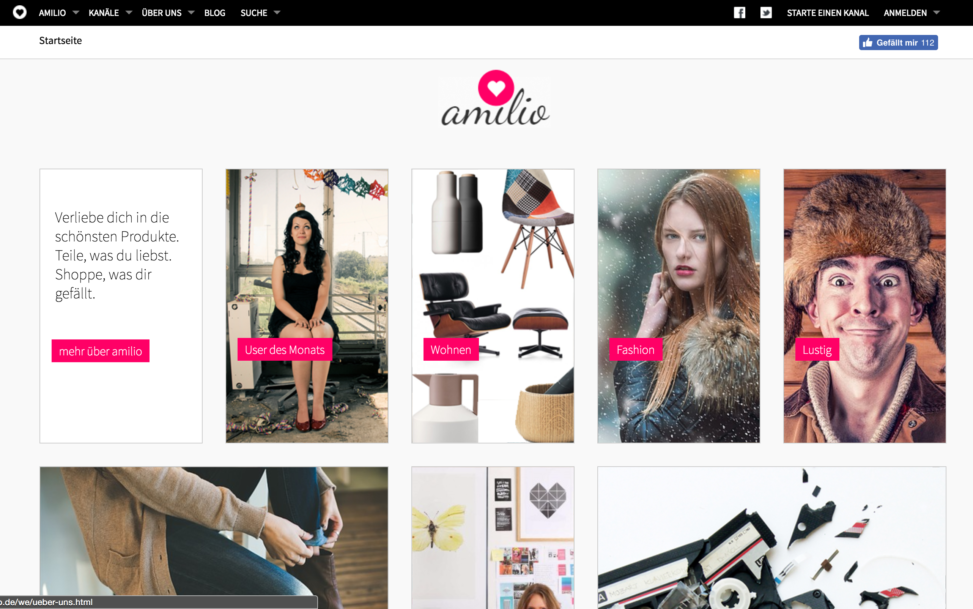
amilio is a shopping community based on affiliate programs. Every user is able create lists of products he or she likes. All those lists and products can be liked and shared by others.
amilio was founded in 2015 by some friends with a technical background. The idea they had was, that everybody is an expert in something. So everybody can recommend products in his or hers domain. amilio builds on top of that idea. When registering you are able to curate product lists of stuff you like. Additionally you can add your affiliate id so you can earn some money with your lists.
Although the idea behind amilio seems to be very promising, the team decided to build a proof of concept first. A good looking proof but still a proof. Paying to much attention to technical details could be a waste of time if you don’t know if a project idea will work.
The amilio platform is deployed continuously via jenkins ci. Therefore it is important to check if the most important features are still working afterwards. Here, the central focus lies on the product lists and collection.
| Page | Rule | Check |
| Home page | The homepage starts with a list of eight curated links. We check if there are eight elements in that list. |
XPath Exists //div[@id=”newestHomepageList”] /div[contains(@class, “item”)] equals 8 |
| Beneath the curated links there is a list of recently created collection. There must be ten of that kind. | XPath Exists //div[@id=”newestChannelsList”] /div[contains(@class, “item”)] equals 10 | |
| It is possible to like products. There is a complex algorithm for calculating the hype factor. As a result there is a list ten products shown on the homepage. |
XPath Exists //div[@id=”newestElementsList”] /div[contains(@class, “item”)] equals 10 | |
| Check if footer is rendered. We believe when one element, like “impressum”, is rendered chances are high that the whole footer is displayed. |
RegEx exists impressum | |
| Check if header is rendered. Just like the footer rule we only check for the existence of one single element. In this case it’s the string “suche”. |
RegEx exists suche | |
| On every product we show in the list view we also provide the like count. This information is fetched via ajax from a json api. As we don’t have a json schema for the endpoint we just check that the answer is well formed. |
JsonValidatoron | |
| User page | On the userpage there are all products and collections of a specific user listed. We created a special user for that case so we can be sure the collections and products do not change. |
|
| The name of the user is visible | RegEx existstestuser | |
| Number of products that can be seen is 10. | CSS Selector exists.productItem equals 10 | |
| Number of collections that can be seen is 10. | CSS Selector exists.channel equals 10 | |
| Collection | A collection page can be checked the same way as the user page. There is a exact number of elements that can be counted. This works although the underlying algorithms are different. |
|
| Product page | As result of our experience the product page does not break very often. As a result we decided to test only some minor attributes. |
|
| Product name and description are visible | RegEx existsNike Air Zoom Pegasus 31 RegEx existscommitment to cushioning |
|
| Collections that contain this exact product are listed | RegEx existsLaufschuhe 2015 | |
| Blog | The blog overview page is a standard collection created by the blog user. This is why the tests for the collection page also apply here. |
|
| The blog articles are almost static. They are fetched via http from an WordPress system in the background. The most tasks are done by WordPress and do not have to be tested following the lean testing approach. Therefore we only check for the headline and a sub-sentence from the post. |
RegEx existsShop, Shop, Hooray. RegEx existsIm Bereich Fashion |
|
| Search | The search result page is technically rendered as evefry other product list. That is why we only have to check if there are products found. As this search query is performed via our solr database we can assume that the system is up and running when there are results. |
CSS Selector exists.productItem equals 10 |
| Sitemap | For a better serach engine optimization we provide a sitemap xml file. This can be checked with the sitemap validator. |
Xml Sitemap Checkeron (non strict) |
| Standard Checks | There are some standard checks that we apply on every html page we tests. | JavaScript Error Scanner on LittleSEOon KoalaPing http status code 200 with timestamp |
